Controversy in Wikipedia Articles
For the main purpose of this project, we generate it from our previous project which is based on an essay called,
Edit wars in Wikipedia and a project called
WikiWarMonitor.
In our previous analysis, we mainly focused on analyzing whether M-statistics,
which is a way to measure the amount of collaboration and conflict in Wikipedia articles or a way to measure the controversy of Wikipedia articles,
is an accurate way or not. In our final conclusion, we found out that M-statistics is not a good way to accurately represents the controversy and conflict of an Wikipedia article.
This conclusion lets us generate the main purpose for this project, which is to find a more accurate weighted sum formula to evaluate the controversy of Wikipedia articles.
In this project, we will analysis some elements like the results from sentiment analysis and find out whether those elements can be used in our weighted sum formula.
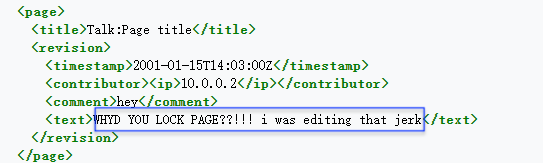
Firstly, Our code starts by downloading the raw XML files from
Wikimedia Data Archives and parsing those files to get the comment content that we
use in our sentiment analysis part.
Secondly, we go to the WikiWarMonitor to get the English Light Dump
that we need in our second part. This is because this file contains the basic information that we will use in our analysis process, s
uch as the article name, revision times, commenters' name and etc. We will use the article name and commenter's name to merge with our comment content.
And we will use revision times to calculate the M-score that we need.
Thirdly, after we merging our comments with the English Light Dump data, we start to use article titles and pageview API to get the raw description number of
views on those articles from those articles' start date to January 1st, 2021
Fourly, we merge all comments, pageview counts with the English Light Dump data and start our analysis to find out elements that will be used in our weighted
sum formula.
To see more details of our research, view our report here.
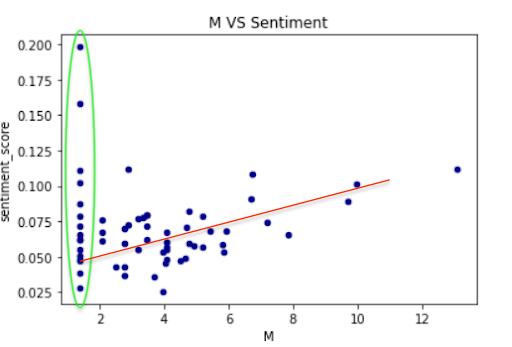
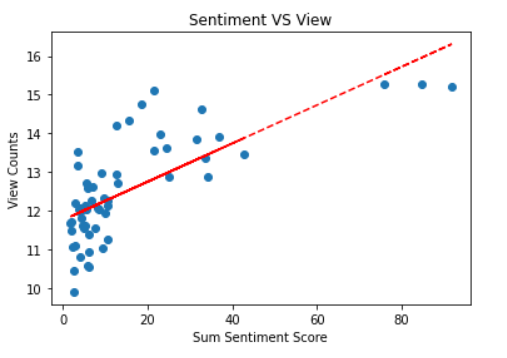
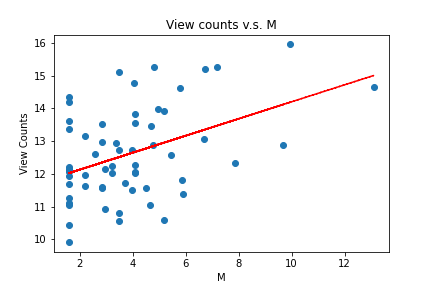
Mean reverts: the percentage of edits for each article;
Mean sentiment score: the mean number of sentiment score for each article's comments;
log(page view counts): the log of views for each article;
log(M): the log of M-score.
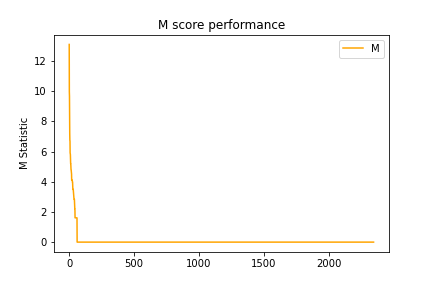

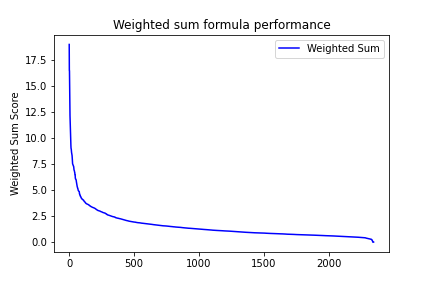
Using this formula, we plot and compare the statistic line with the original measurement (M statistic), and find out the most improvement is we successfully make the slope smoother (see the right figure). Although there is still a steep decrease within top 5% articles, we considered this more likely to be a feature in Wikipedia that most articles are relatively “boring” than a drawback of our measurement.